Introduction
The Om language is:
- a novel, maximally-simple concatenative, homoiconic programming and algorithm notation language with:
- minimal syntax, comprised of only three elements.
- prefix notation, in which functions manipulate the remainder of the program itself.
- panmorphic typing, allowing programming without data types.
- a trivial-to-parse data transfer format.
- unicode-correct: any UTF-8 text (without byte-order marker) defines a valid Om program.
- implemented as a C++ library and:
- embeddable into any C++ or Objective-C++ program.
- extensible with new data types or operations.
The Om language is not:
- complete. Although the intent is to develop it into a full-featured language, the software is currently at a very early "proof of concept" stage, requiring the addition of many operations (such as basic number and file operations) and optimizations before it can be considered useful for any real-world purpose. It has been made available in order to demonstrate the underlying concepts and welcome others to get involved in early development.
- stationary. Om will likely undergo significant changes on its way to version 1.0.
License
This program and the accompanying materials are made available under the terms of the Eclipse Public License, Version 1.0, which accompanies this distribution.
For more information about this license, please see the Eclipse Public License FAQ.
Using
The Om source code can be used for:
- Building a stand-alone interpreter from a script-generated build project.
- Including as a C++ header-only library.
Downloading
The Om source code is downloadable from the Om GitHub repository:
- The Development version (to which this documentation applies) can be obtained via Git clone or archive file.
- Released versions can be obtained via archive files from the GitHub tags page.
Dependencies
Programs
To run scripts which build the dependency Libraries and generate the build project, the following programs are required:
- CMake
- Mac OS X:
- Xcode
- Windows:
- Visual Studio
- Cygwin (with bash, GNU make, ar, and ranlib)
- Ubuntu:
- Build-Essential package (
sudo apt-get install build-essential)
- Build-Essential package (
To build the Documentation in the build project, the following additional programs are required:
To ensure that correct programs are used, programs should be listed in the command line path in the following order:
- Graphviz, Doxygen, and CMake
- Cygwin ("[cygwin]/bin") (Windows only)
- Any other paths
Libraries
The following libraries are required to build the Om code:
Building
A build project, containing targets for building the interpreter, tests, and documentation, can be generated into "[builds directory path]/Om/projects/[project]" by running the appropriate "generate" script from the desired builds directory:
- "generate.sh" (Unix-based platforms)
- "generate.bat" (Windows, to be run from the Visual Studio command line)
Arguments include the desired project name (required), followed by any desired CMake arguments.
By default, this script automatically installs all external dependency libraries (downloading and building as necessary) into "[builds directory path]/[dependency name]/downloads/[MD5]/build/[platform]/install". This behaviour can be overridden by passing paths of pre-installed dependency libraries to the script:
-D Icu4cInstallDirectory:Path="[absolute ICU4C install directory path]"-D BoostInstallDirectory:Path="[absolute Boost install directory path]"
Interpreter
The Om.Interpreter target builds the interpreter executable as "[Om build directory path]/executables/[platform]/[configuration]/Om.Interpreter". The interpreter:
- Accepts an optional command-line argument that specifies the desired UTF-8 locale string. The default value is "en_US.UTF-8".
- Reads input from the standard input stream, ending at the first unbalanced end brace, and writes output to the standard output stream as it is computed.
Test
The Om.Test target builds the test executable, which runs all unit tests, as "[Om build directory path]/executables/[platform]/[configuration]/Om.Test". These tests are also run when building the RUN_TESTS target (which is included when building the ALL_BUILD target).
Documentation
The Om.Documentation target builds this documentation into the following folders in "[Om build directory path]/documentation":
- "html": This HTML documentation. To view in a browser, open "index.html".
- "xml": The XML documentation, which can be read by an integrated development environment to show context-sensitive documentation.
Including
Om is a header-only C++ library that can be incorporated into any C++ or Objective-C++ project as follows:
- Add the Om "code" directory to the include path and include the desired files. Inclusion of any operation header files will automatically add the corresponding operation to the global system. Include "om.hpp" to include all Om header files.
- Configure the project to link to the code dependencies as necessary, built with the correct configuration for the project. See the dependency "build.cmake" scripts for guidance.
- Call the
Om::Language::System::Initializefunction prior to use (e.g. in themainfunction), passing in the desired UTF-8 locale string (e.g. "en_US.UTF-8"). - Construct an
Om::Language::Environment, populate with any additional operator-program mappings, and call one of itsOm::Language::Environment::Evaluatefunctions to evaluate a program.
For more in-depth usage of the library, see the Om code documentation.
Language
Syntax
An Om program is a combination of three elements—operator, separator, and operand—as follows:

Operator
An operator has the following syntax:
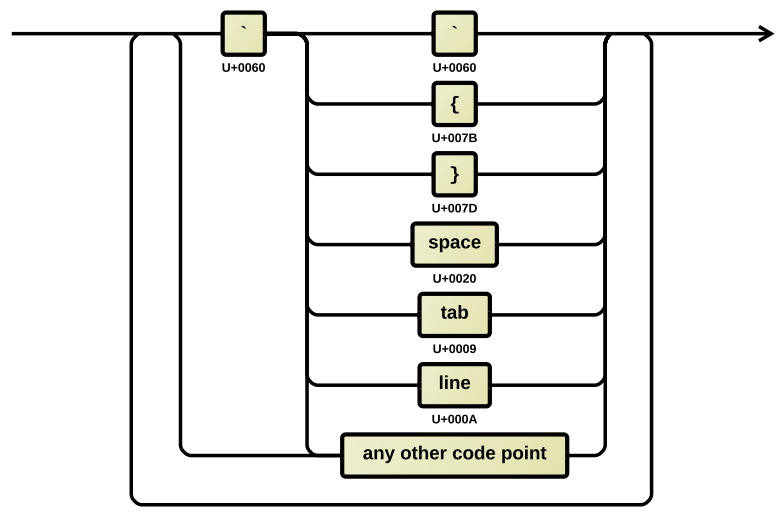
Backquotes (`) in operators are disregarded if the code point following is not a backquote, operand brace, or separator code point.
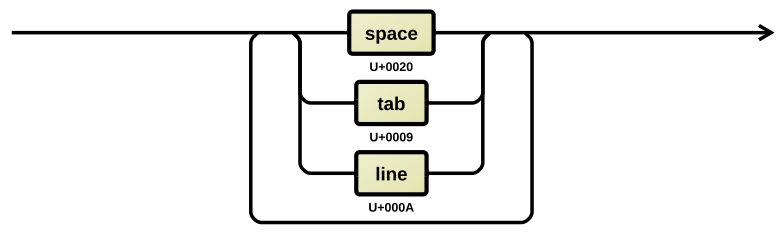
Separator
A separator has the following syntax:
Operand
An operand has the following syntax:

Functions
The Om language is concatenative, meaning that each Om program evaluates to a function (that takes a program as input, and returns a program as output) and the concatenation of two programs (with an intervening separator, as necessary) evaluates to the composition of the corresponding functions.
Prefix Notation
Unlike other concatenative languages, the Om language uses prefix notation. A function takes the remainder of the program as input and returns a program as output (which gets passed as input to the leftward function).
Prefix notation has the following advantages over postfix notation:
- Stack underflows are impossible.
- Prefix notation more closely models function composition. Instead of storing a data stack in memory, the Om evaluator stores a composed partial function.
- The evaluator can read, parse and evaluate the input stream in a single pass, sending results to the output stream as soon as they are evaluated. This cannot be done with a postfix, stack-based language because any data on the stack must remain there as it may be needed by a function later.
- Functions can be optimized to only read into memory the data that is required; stack-based postfix languages have no knowledge of the function to apply until the data is already in memory, on the stack.
- Incoming data, such as events, become simple to handle at a language level: a program might evaluate to a function that acts as a state machine that processes any additional data appended to the program and transitions to a new state, ready to process new data.
- An integrated development environment can provide hints to the user about the data that is expected by a function.
Evaluation
Only the terms (operators and operands) of a program are significant to functions: separators are discarded from input, and are inserted between output terms in a "normalized" form (for consistent formatting and proper operator separation).
There are three fundamental types of functions:
- Identity: A function whose output program contains all the terms in the input program.
- Constant: A function whose output program contains a term, defined by the function, followed by all terms in the input program.
- Operation: A function that is named by an operator and defines a computation. An operation processes operands at the front of the input program as data for the computation, and pushes any terms generated by the computation onto the output program, until one of two things happens:
- If the computation is completed, the rest of the input terms are pushed onto the output program.
- If the computation cannot be completed (due to insufficient operands), the operator that names the operation is pushed onto the output program, followed by all remaining input terms.
Programs are evaluated as functions in the following way:
- The empty program evaluates to the identity function.
- Programs that contain only a single element evaluate to functions as follows:
- Separator: Evaluates to the identity function.
- Operand: Evaluates to a constant function that pushes the operand, followed by all input terms, onto the output program.
- Operator: Evaluates to the operation defined for the operator in the environment. If none, evaluates to a constant function that pushes the operator, followed by all input terms, onto the output program.
- Programs that contain multiple elements can be considered a concatenation of sub-programs that each contain one of the elements. The concatenated program evaluates to the composition of the functions that each sub-program evaluates to.
For example, program "A B" is the concatenation of programs "A", " ", and "B". The separator evaluates to the identity operation and can be disregarded. The programs "A" and "B" evaluate to functions which will be denoted as A and B, respectively. The input and output are handled by the composed function as follows:
- Function
Breceives the input, and its output becomes the input for functionA. - Function
Areceives the input, and its output becomes that of the composed function.
Any programs may be concatenated together; however, note that concatenating programs "A" and "B" without an intervening separator would result in a program containing a single operator "AB", which is unrelated to operators "A" or "B".
Operations
All operation implementations provided are documented in the Operation module.
Data
There are no traditional data types in the Om language: every data value is represented by an operand.
Panmorphism
The Om language uses a unique panmorphic type system, from Ancient Greek πᾶν (pan, "all") and μορφή (morphē, “form”), in which all data values are exposed exclusively through a common immutable interface.
In the case of the Om language, every data value is entirely represented in the language as an operand. Any operation will accept any operand as a valid input and interrogate its data solely through its contained program (a sequence of operator, separator, and/or operand). The operation is then free to process the data however is appropriate, and any operand that it produces as output can then be interrogated and processed by the next operation in the same way.
Implementation
Although any operand can be treated as containing a literal array of operand, operator and/or separator elements, the implementation of operands takes advantage of some optimizations:
- Each operand in memory actually contains one of several possible program implementations, each optimized for a specific set of operations. For example, some operations treat separators as insignificant; operands produced by these operations could contain a program implementation that stores only terms (operators and/or operands) and presents a "normalized" separator (such as a line separator) between each term.
- Operations can interrogate an input operand for its program implementation type; if it is the optimal implementation type for the operation, the operation can manipulate the operand directly to produce the same result more efficiently.
Operations in a program can be ordered by the programmer to increase performance by minimizing conversions between program implementations, but it is not necessary for obtaining a correct computation. Where relevant, an operation will document the program implementation types of its inputs and outputs to allow for this optional level of optimization.
Programs
All program implementations provided are documented in the Program module.
Examples
The following program contains a single operand containing an operator "Hello,", a separator " ", and another operator "world!":
{Hello, world!} |
{Hello, world!} |
The following program contains a single operand containing an operator "Hello,", a separator " ", and an operand "{universe!}" which in turn contains a single operator "universe!":
{Hello, {universe!}} |
{Hello, {universe!}} |
Note that separators are significant inside operands:
{Hello, world!} |
{Hello, world!} |
Operands can be dropped and copied via the drop and copy operations:
drop {A}{B}{C} |
{B}{C} |
copy {A}{B}{C} |
{A}{A}{B}{C} |
drop copy {A} |
{A} |
copy copy {A} |
{A}{A}{A} |
The drop operation can therefore be used for comments:
drop {This is a comment.} {This is not a comment.} |
{This is not a comment.} |
The choose operation selects one of two operands, depending on whether a third is empty:
choose {It was empty.}{It was non-empty.}{I am not empty.} |
{It was non-empty.} |
choose {It was empty.}{It was non-empty.}{} |
{It was empty.} |
An operation without sufficient operands evaluates to itself and whatever operands are provided:
drop |
drop |
choose {It was empty.}{It was non-empty.} |
choose{It was empty.}{It was non-empty.} |
The quote and dequote operations add and remove a layer of operand braces, respectively:
quote {B} |
{{B}} |
dequote {{B}} |
{B} |
dequote {copy} |
copy |
dequote {copy} {A} |
{A}{A} |
Operands can be popped from and pushed into:
<-[characters] {ABC} |
{A}{BC} |
->[literal] {A}{BC} |
{ABC} |
<-[terms] {some terms} |
{some}{terms} |
A new operator definition can be provided with the define operation, where the first operand is treated as containing a Lexicon with operator-to-operand mappings, and the second operand contains the program to evaluate using the defined operator:
define { double-quote {quote quote} } { double-quote {A} } |
{{{A}}} |
Any string can be used as an operator, with separators and operand braces escaped with a backquote:
define { double` quote {quote quote} } { double` quote {A} } |
{{{A}}} |
<-[terms] { double` quote operator } |
{double` quote}{operator} |
Unicode is fully supported:
<-[characters] {한글} |
{한}{글} |
<-[code` points] {한글} |
{ᄒ}{ᅡᆫ글} |
<-[terms] {한글 韓} |
{한글}{韓} |
Strings are automatically normalized to NFD, but can be explicitly normalized to NFKD using the normalize operation:
normalize {2⁵} |
{25} |
Recursion is very efficient in the Om language, due to (a) the "eager" evaluation model enabled by prefix concatenative syntax (i.e. data is consumed immediately rather than being left on a stack), and (b) the non-recursive evaluation implementation in the evaluator that minimizes memory overhead of recursive calls and prevents stack overflow. The following example uses recursion to give the minutes in a colon-delimited 24-hour time string:
define |
{23} |
An important feature of Om is that each step of an evaluation can be represented as a program. The following is the above program broken down into evaluation steps, where the code that is about to be replaced is bold, and the latest replacement is italicized:
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
define |
{23} |
The rearrange operation provides operand name binding, allowing for a more applicative style. The following example is a simplistic implementation of a left fold, along with an example call:
The result is {321}.
The example works as follows:
[Fold]<-takes three operands:FunctionBaseSource
- The first term is popped from the
Source. - The
Functionis applied to:- the
Base - the popped first term of the
Source - the remainder of the
Source - the remainder of the input program
- the
- The first two operands output by the
Functionare:ResultRemainder
- If the
Remainderis empty, theResultis output. Otherwise,Function,Result, andRemainderare passed to a recursive[Fold]<-call.
A few things should be noted about the above example:
- The Operation list is very short at the moment; as it expands, higher-level constructs should allow for simplification of algorithms such as this one.
- When reading Om code, it can be difficult to mentally group operations with the operands they consume (contrasted with Scheme, in which they are grouped at design time with parentheses). However, it should be possible for an Om integrated development environment to generate a graphical indication of these groupings dynamically.
Contributing
There are several ways to contribute to the Om project:
- By Developing new Operation and Program classes.
- By Reporting Issues via bugs, patches, or enhancement requests.
- By Funding further development of the Om language.
Developing
Om is written in modern, portable C++ that adheres to the Sparist C++ Coding Standard.
Note: Because this is an early-stage project, there are not yet any compatibility guarantees between versions.
Forking
Om code can be forked from the Om GitHub repository.
Building
See the Using section for instructions on building the code.
Adding or Removing Files
When adding or removing files from source, re-run the "generate" script from the build directory to update the project.
Adding Operations
Additional native functionality can be added to the Om language by implementing new operations in C++.
There are two ways to implement an operation: as a composite operation, or an atomic operation.
To implement a composite operation, or an atomic operation that consumes no operands:
- Define the operation
classin theOm::Language::Operationnamespace. - Define the static
GetName()method, which returns astatic char const *containing the name. - Define the static
Give(Om::Language::Evaluation &)method, with no return value, to give existing operations and/or elements to the evaluation.
To define an atomic operation that consumes one or more operands:
- Define the operation
class, derived fromOm::Language::Operation::DefaultIncompleteOperation(which has the operationclassas its template argument), in theOm::Language::Operationnamespace. - Define the static
GetName()method, which returns astatic char const *containing the name. - Implement the functions necessary to compile.
- Optionally override virtual function implementations in
Om::Language::Operation::DefaultIncompleteOperationthat may be more optimally implemented in the operation.
For any operation implementation, code must be added to the operation header that inserts the operation into the system when the header is included, as follows (where WhateverOperation is a stand-in for the name of the operation class):
Adding Programs
New data types can be added to the Om language by extending Om::Language::Program and defining the functions necessary to instantiate the class. Use existing programs as a guide.
Program types should be defined in the Om::Language namespace.
Analyzing Code
Some basic free static analysis tools can be applied to the Om code:
- HFCCA is a Python script that measures cyclomatic complexity and counts the number of lines of code in C++ source files, not including comments or tests. If Python is installed and in the path, HFCCA can be applied to Om by entering the following at the terminal from inside the Om directory:
python [path]/hfcca.py -p -v code - CLOC is a stand-alone Perl script that determines total line counts. If Perl is installed, CLOC can be applied to Om by entering the following at the terminal from inside the Om directory:
[path]/cloc.pl code
Analyzing Test Coverage
The Om.Test target of the Xcode project generates test coverage data that can be viewed as follows:
- Download and install CoverStory. In Preferences, add
"*.ipp"and"*.hpp"to the "SDK Files" list. - Build and run the Om.Test target.
- In the CoverStory File menu, open the folder "[Om build directory path]/projects/Xcode/Om.build/[configuration]/Om.Test.build/Objects-normal/x86_64", where [configuration] is the build configuration (e.g. "Debug", "Release"). The main CoverStory window should be populated as follows:
- The left pane shows a list of Om source files, each accompanied by a test coverage percentage.
- The right pane shows the contents of the currently selected source file, with each line annotated with the number of times it was executed.
Submitting Changes
Changes can be submitted to Om via pull request.
Reporting Issues
Issues are reported and tracked with the Om GitHub issue tracker.
Before reporting an issue, please search existing issues first to ensure that it is not a duplicate.
Funding
The Om language is currently a spare-time project of one person. If you would like to speed the development of the Om language in either a general or domain-specific direction, please contact me at information@sparist.com.
References and Thanks
The following additional reading may help explain some of the concepts that contributed to the Om language:
- Why Concatenative Programming Matters
- The Concatenative wiki, mailing list, and Wikipedia entry
- A mirror of Manfred von Thun's original pages on the groundbreaking Joy Programming Language (Wikipedia entry), the father of all concatenative languages
Thanks to all of the people who contributed to:
- The libraries and tools that the Om implementation makes use of
- The technologies and ideas that Om builds on
- Om itself, in the form of bug reports, feedback, and encouragement